I live next to a train. To be more specific, the desk I am currently typing on is approximately 200 ft from the tracks. I have become somewhat immune to the shockingly loud train horns that trumpet several times each day and literally shake my apartment. Still, I began wondering if there is any rhyme or reason to the train’s schedule.
For fun, and as a sanity test to confirm whether I am actually hearing trains in the middle of the night or I’m hallucinating, I began working on a train detector. Given the microphone input on my computer, I wanted to continuously monitor environmental noise, detect anomalies, and then classify these anomalies as train or no train. All code for this project can be found on my github.
While this is an easy problem from a machine learning standpoint with train horns being comically unique amongst other residential sounds, it was an enjoyable project and I now know: I am waking up in the middle of the night because of the train!
Collecting Data: All Trains are Loud

The first step is to know what might be a train. This is fairly simple: all trains are loud. By law, they must sound their air horn at every road crossing to alert distracted drivers. They must be louder than any headphones or blaring speakers in a car. To avoid overrecording, I added a few more characteristics, like a minimum duration for the noise and a maximum duration for quietness.
The pseudocode is
if LOUD_NOISE:
start_recording()
if recorded_noise is loud and long:
# it is a possible train if its loud and long
save_recording()
In order to determine how loud a train is, I recorded a passing train and looked at its sound amplitude to determine a reasonable cutoff. At this point, I was effectively saving all clips of loud noises. The only problem is, of course, that not all loud noises are trains.
Training a Classifier: Not All Loud Noises are Trains
Once I collected some data, I began to label each sound clip. The clips of train horns are a “1” and the other loud noises (my vacuum cleaner, music, particularly intense typing, putting away dishes, my cop neighbor’s obnoxious straight-piped Mustang, etc.) are a “0.” Indeed, I listened to hundreds of recordings and hand-labeled the ones that were trains.
So how hard can it be? Well, I began with some exploratory data analysis. First, I plotted the audio files in the time domain. This was a whole lot of nonsense. The train horn is a long loud noise and then silence, while the other loud noise has spurts of high amplitude. How would I quantify these features? Moreover, what if a train horn sounds while I’m vacuuming?
| Train Horns | Other Loud Noises |
|---|---|
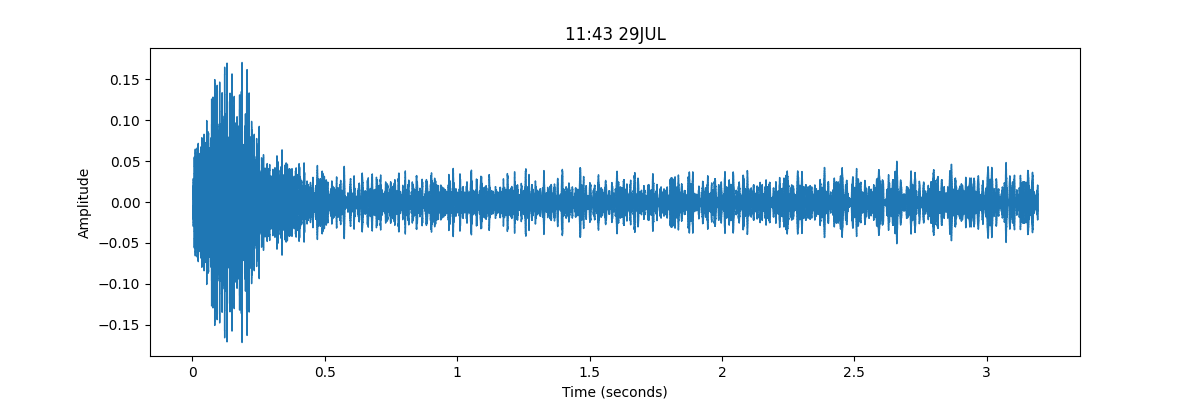 |
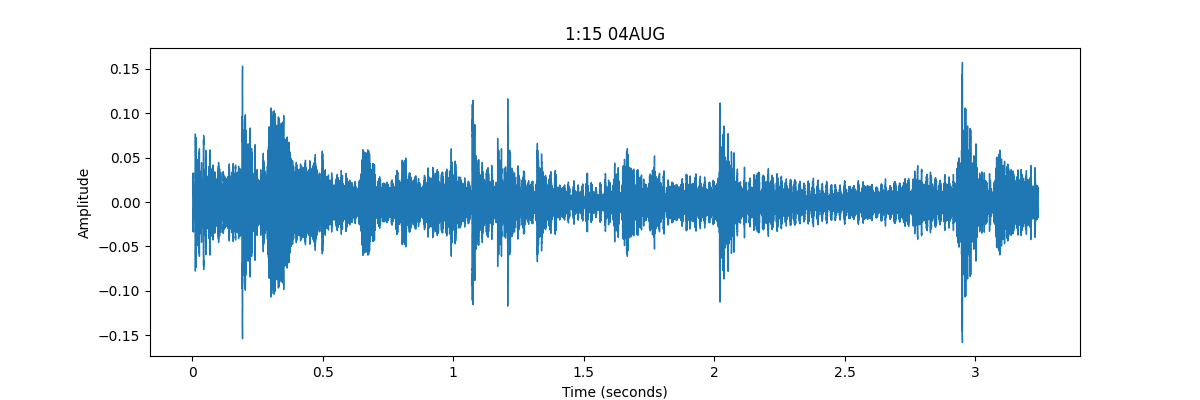 |
I tried in vain to use the magnitude by finding the beginning and end of the loud noise and looking at how loud and long it was. But I wasn’t getting anywhere: different conductors have different styles when sounding their horn: some are brief, others let it sound for a sadistic 10 seconds. Moreover, they may sound the horn at different points on their routes, which will register at different magnitudes for my laptop microphone. So magnitude and duration alone are insufficient to pinpoint a train horn.
I had the sixth sense that I needed the Fourier transform. While I have only a cursory understanding of the Fourier transform, I do know it converts a wave from the time domain to the frequency domain. In other words, you can see your sound decomposed into all its component frequencies.
So I plotted the frequency breakdown of all my audio clips of each type and compared the graphs. The main difference is pretty obvious: the train horn sounds have much higher frequencies than other household sounds.
| Train Horns | Other Loud Noises |
|---|---|
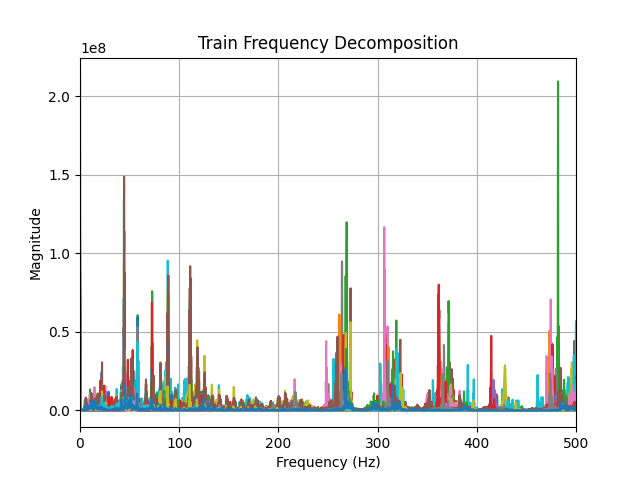 |
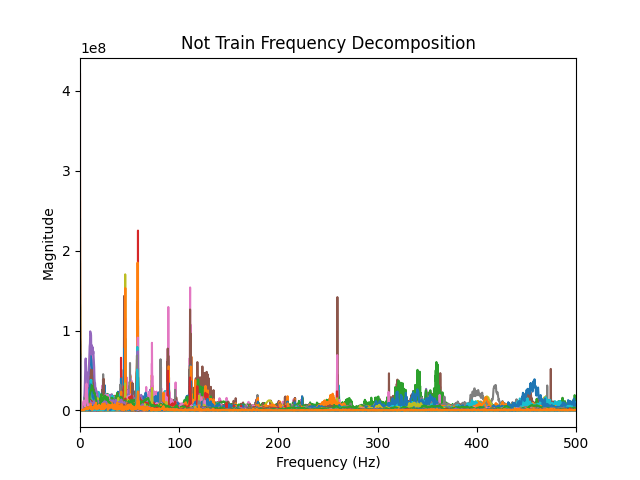 |
So, it was time to engineer features. I used frequency bins, where I took the sum of all magnitudes within a given subset of the frequency spectrum. For example, one bin might be the sum of all signal between 400 and 450. I also used the length of the “pulse” in the sound magnitude. This was an attempt to distinguish short, loud sounds like the clanking of dishes, from more sustained loud sounds like a train horn. I decided to use a random forest classifier for its easy interpretability and reduced risk of overfitting. I defined my features with three parameters:
- Lowest frequency: the minimum frequency that is included in the beginning
- Highest frequency: the maximum frequency that is included in the beginning
- Number of bins: Between lowest and highest, how many bins we use to divide up the frequency spectrum
My final dataset included 1,296 audio files, 83 of which were trains. My limited grid search determined that the best feature set used 20 equally-spaced bins between frequencies 400 and 950. I used k-fold cross validation with 5 folds. The classifier offers an accuracy of 99.6%, with disappointing 95% for the only thing I care about: precision of train detecting. Below, I’ve included a confusion matrix as well as the classification report.
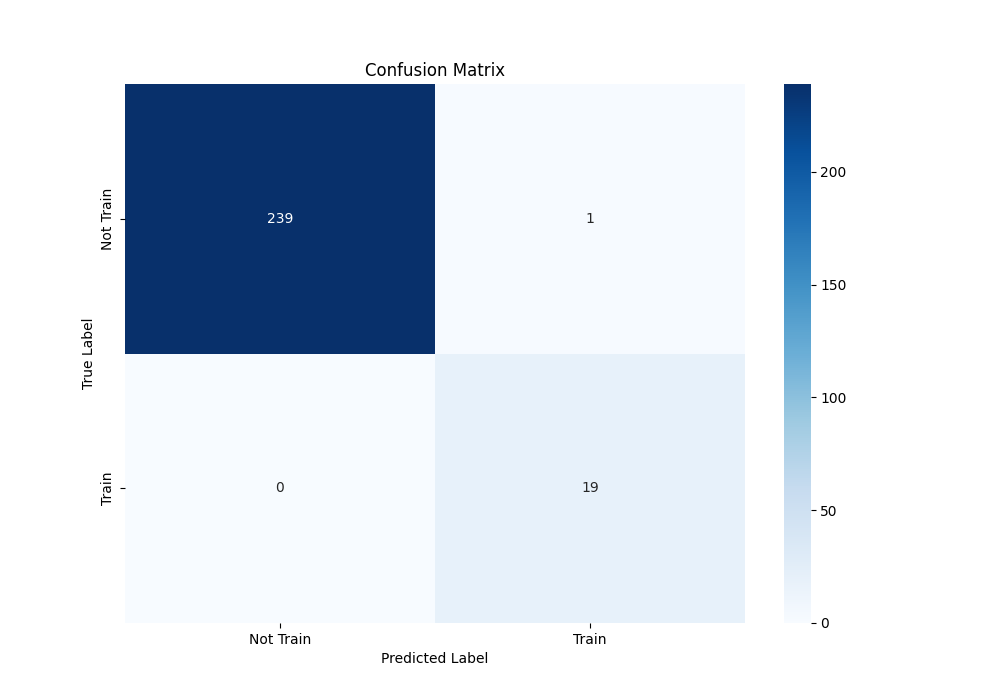
Classification Report:
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Not Train | 1.00 | 1.00 | 1.00 | 240 |
| Train | 0.95 | 1.00 | 0.97 | 19 |
| Accuracy | 0.996 | 259 |
What Maketh a Train Horn?
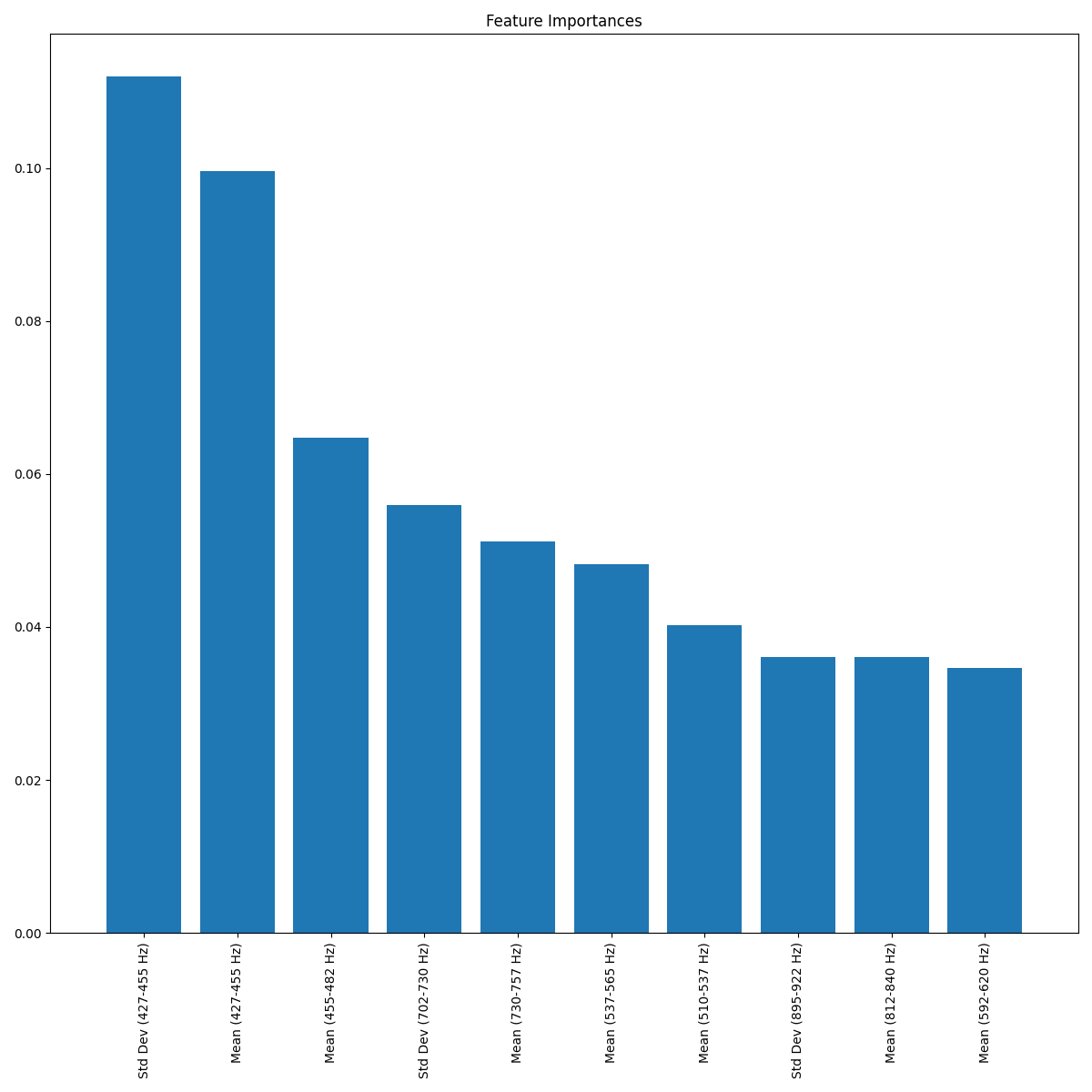
Below, I’ve plotted the weights of the ten most important features in the model. The rest are more or less uniformly important. This basically shows us the frequency ranges that most train horns are in: 400-450 ish, as seen in the plot of the Fourier transforms. Interestingly enough, my feature that measured the length of the loud noise was not significant at all…
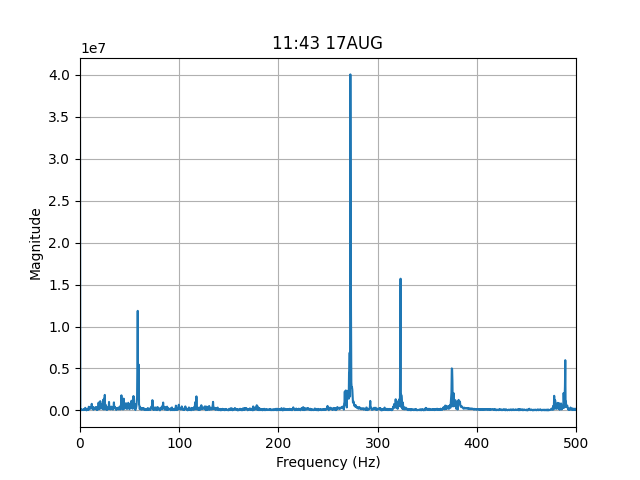
This provides some insight if we look at the missed train horns below:
| Undetected Train Horn #1 | Undetected Train Horn #2 |
|---|---|
 |
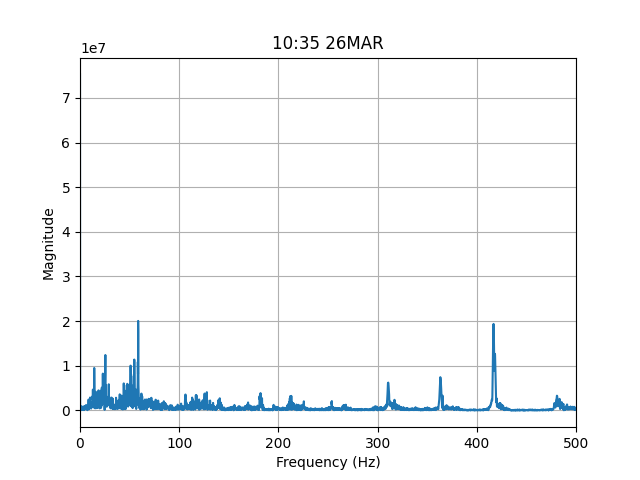 |
The first train horn has a big frequency spike below 300 Hz, which the model doesn’t even consider, while the second is quite muted. I can live with this for the moment. It takes far less than perfection to satisfy my curiosity.
Bootstrapping Model
It’s kind of annoying to record loud noises and then manually label them… I end up getting hours of my wife listening to music in the apartment and every sharp noise that attends emptying the dishwasher or cooking dinner. That is the principal reason I have over a thousand “non train” loud noises. I considered trying to “bootstrap” the model by manually vetting detected train sounds and then adding them to the dataset. The problem is, my model has a tendency to miss trains, rather than mislabel non-trains. If I bootstrap the model, I won’t add any more false negatives (which are what I need!) but I will get more false positives. This could work if I massively increase my dataset and can support more variables and interactions in the model.
Results
I modified my original data collection script to check if a recording was a train and then save it.
if noise is loud:
current_noise = record_now()
if current_noise is loud:
# if it's a loud noise, start recording. it may be a train!
recorded_noise = record_until_loud_noise_ends()
if classifier.is_train(recorded_noise):
print("found a train! at {time}")
save_recording()
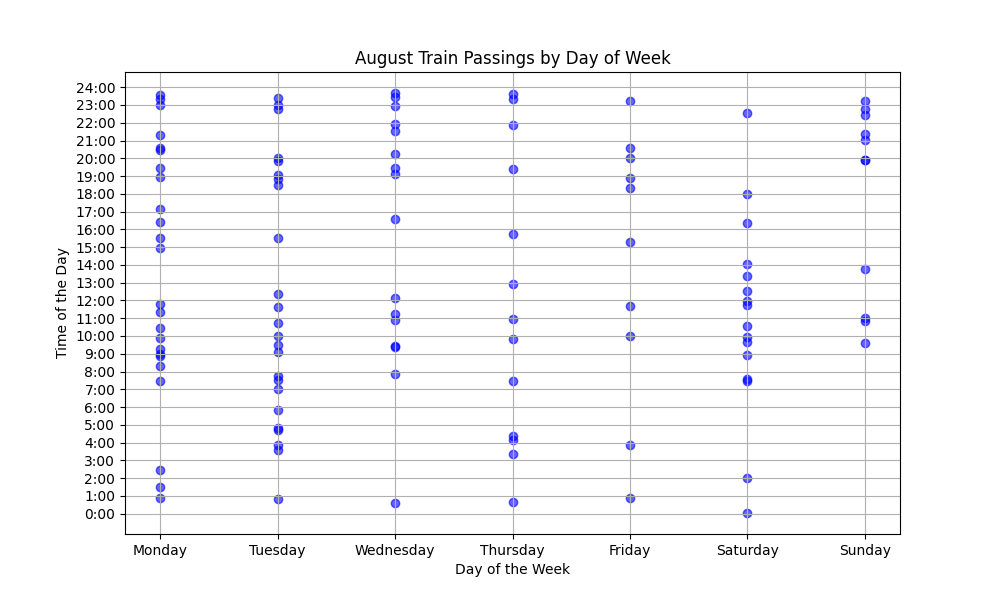
So, what does the train schedule look like? Here is the month of August, where each dot represents a unique train coming by my apartment. You can see some clustering by day around certain times. One thing I appreciate is they try to avoid rush hour if they can, as it really recks traffic in the downtown area, where the train crosses almost every street. They also feel free to come in the middle of the night. There does appear to be some sort of rhythm.
Below, I show all data I collected (240 trains, give or take). This reinforces the idea that trains cluster around 4-6 hour bands throughout various days of the week, with rush hour being mostly protected.
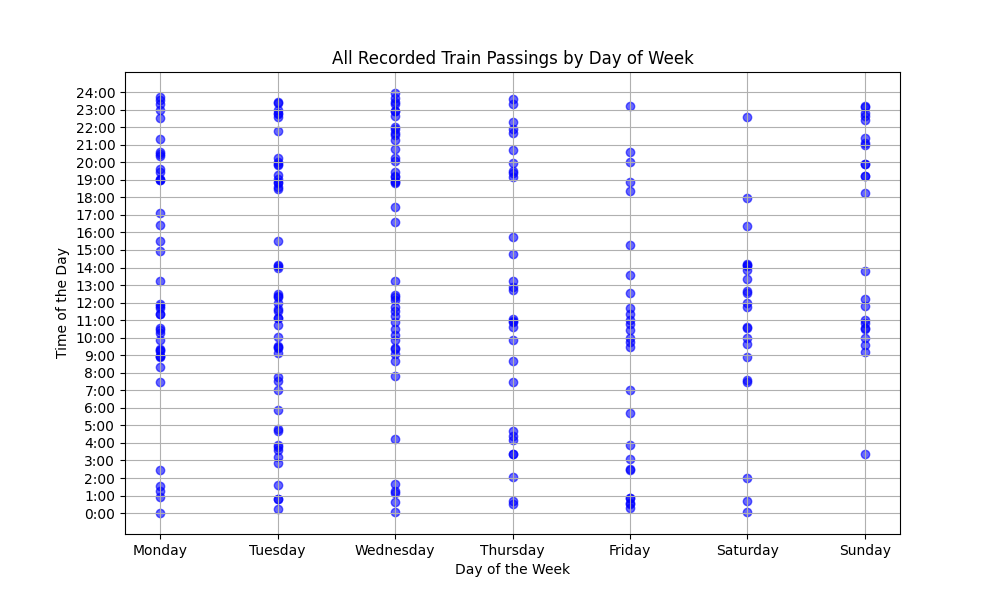
In conclusion, the train comes all the time! On average, it comes 27 times a week, and this is certainly an underestimate due to poor recording (more info in pitfalls). The two weeks I had of undisturbed recording detected 46 and 58 trains, for an average of 7-8 trains per day. Perhaps I will publish this information on a Google review for my apartment complex… I sure wish I had known!
Pitfalls
I am missing quite a few trains. First, I miss trains because my model mislabels them as false. This is pretty rare, but it does hapepn. Second, I may miss them because I am using my computer or making some other noise. Finally, using your computer microphone to perpetually record your environment is a bad idea! Whenever I mess with my computer peripherals, the link between the script and the microphone are broken and the thing doesn’t record any noises. This seems to happen at random, in addition to when I plug headphones in or unplug my computer from its monitor.