As this is a lengthy and somewhat technical post, here’s a summary. The AIM marketplace matches officers with their next assignment. After resume exchanges and interviews, officers and units each submit a ranking of their preferences. Then, human resources runs the Gale-Shapley algorithm to determine the matches. However, there is considerable scheming in the form of both parties revealing/lying about their preferences and units pressuring officers to rank them highly. I wanted to understand how varying degrees of scheming affected the optimality of the match and, in particular, whether rule breaking was incentivized under these conditions. I found that rule breaking is advantageous under almost all circumstance for both units and officers. Those that don’t break the rules perform worse on average. The rule breaking allows both units and officers to outperform the Gale-Shapley baseline. There are a number of limitations to these findings based on the simplifications inherent in modeling a complicated, dynamic process.
Introduction
I recently participated in my first “AIM marketplace,” the Army’s new-ish method for slating Army officers for new jobs. I was unprepared for how much strategy would be involved! After it closed, I wondered if I had played the game optimally. To answer this question, I simulated thousands of marketplaces to analyze the dynamics of the marketplace under different conditions. The following post explains the marketplace (both its design and actual implementation), my modeling approach, my noteworthy results, and, finally, some recommendations for improvement. All code can be found on github.
AIM Marketplace: Design
If you’re familiar with the residency match for U.S. medical students, this is supposed to be a carbon copy. Here’s how its supposed to work:
- Units conduct interviews with officers. Each party uses the time before the marketplace “closes” to research opportunities and develop an ordered list of preferences. The end result for the unit is a ranking of all officers and vice versa.
- Units and officers don’t reveal their preferences before the market closes, except through the official signaling in the marketplace (employers and officers can both see if the other has ranked them in their top five more or less).
- Once the marketplace closes, preferences are locked and HRC runs the Gale-Shapley algorithm to create a “stable matching.” A stable matching is one where no unit and officer would benefit from swapping choices with another unit-officer pair.1
- Two-ish months later, after some HRC sausage-making, you find out where you’re going.2
What Actually Happens
Do people reveal their preferences before the match? Hell yeah. Units try to bypass the uncertainty of Gale-Shapley and arrange “one-for-one” matches thereby guaranteeing that when the algorithm runs, they will get their match of choice because they know their first choice has ranked them first. They do this by revealing their preferences to their top officer choice and seeking a verbal commitment that he or she will in turn rank them first.
I had an interesting realization, as I found myself receiving an exploding offer from a particularly frenetic unit. In this case, the Gale-Shapley algorithm is an emergent phenomenon; the individuals making the matches do an approximate version of it before the deadline. Here’s how the typical unit operates from what I gathered:
- Once they have their list of preferences, they reach out to their top choice.
- If the top choice doesn’t accept, they reach out to the next person on the list. And so on, until they have a “one-for-one” match.
- They change their actual rankings to try to land at a “one-for-one.” While some pairs are unmatched by the time the market closes, I would venture to guess a majority of employers/officers get their “first choice,” which is highly impacted by the side channels.
For those familiar with the Gale-Shapley algorithm, this is basically exactly how it works. Suitors make offers to their top choice until someone accepts, and the choices accept the best offers as they come along. There is an added twist, however, because each party can trick the other when this is done through side channels. For example, a unit may offer multiple “one-for-one” matches and thus an officer may think they have a “one-for-one” when they don’t. Or an officer may mislead a unit about his/her preferences.
After going through this process and receiving pressure to commit to a job that was not my top choice, I wondered what price I might pay for my honesty. Here was the scenario:
- A unit revealed I was their top choice and requested a response.
- They were my second choice. I had two options:
- Tell them they are my second choice (effectively denying the offer) and risk them likely finding someone else to place first.
- Tell them I accept the match and they are my top choice as I don’t currently have a better offer.
This dilemma made me curious about the dynamics in a marketplace and how they might be impacted by “defectors.” I came up with the following research questions:
- How does the emergent psuedo-Gale-Shapley algorithm compare to the actual algorithm as far as the success of the match?
- What happens to the rule-followers who don’t seek “one-for-one” matches? Is it better to break the rules?
Modeling the Marketplace
Below, I detail my steps for simulating the marketplace. First, I explain how I simulated data and then how the procedure works.
Simulating Data
First, I don’t have any actual data (yet) so I had to rely completely on simulated data. The modeling is fairly simple.
Let $U_i$ be a unit and $O_i$ be an officer. Assume each unit and officer has an endogenous desirability that follows a normal distribution. That is, some units every officer wants to match with (Colorado), some units no one wants to match with (Louisiana), and most units are somewhere in the middle. The same applies to officers (some studs, some duds, most are average).3
\(U_i \sim N(50, 20)\) \(O_i \sim N(50, 20)\)
In addition to a unit’s endogenous desirability, there is also a component of desirability that comes from the officer. For example, Louisiana may have a low desirability, but an officer might have family there and thus really want to move there. We account for this by adding another random variable, or some “noise,” to the mix:4
\(O_i(U_j) \sim N(0, 20)\) \(U_i(O_j) \sim N(0, 20)\)
To recap, each officer will evaluate a unit based on its innate desirability and its specific desirability to that officer. Then, an officer or unit ranks their choices according to the following desirability scores:
\(D_{O_i}(U_j) = U_j + O_i(U_j)\) \(D_{O_i}(A_j) = O_j + U_i(O_j)\)
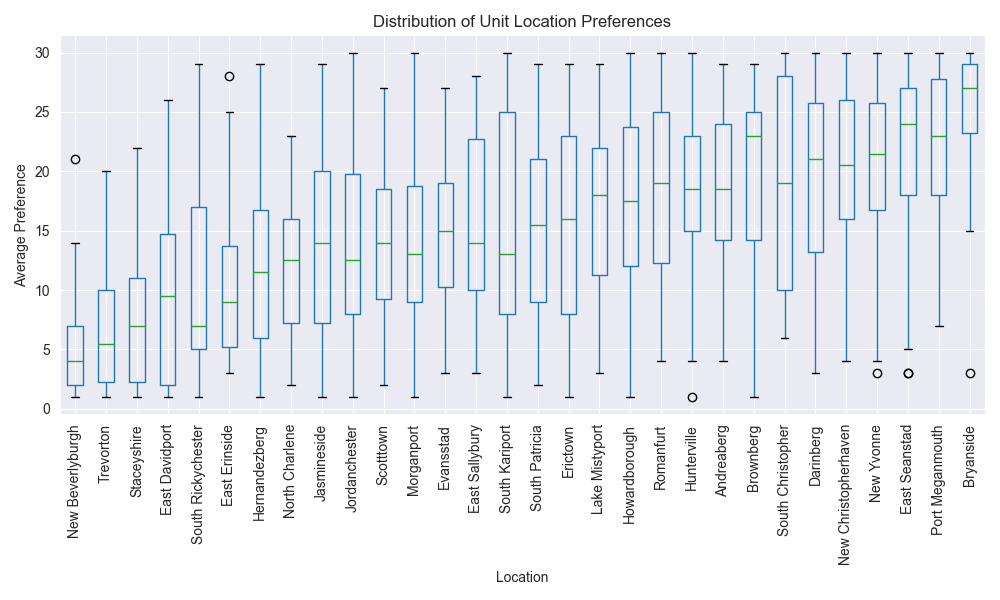
The following chart conveys the distribution of one sample of simulated data. There is a boxplot of the distribution of rankings for each unit for a marketplace of size 30. You can see some units are much more highly preferenced than others, but because of the added unit-specific desirability of each officer, even the least desirable units receive some high rankings.
Agents
The next step is to define the way units and officers behave during the marketplace. I am exploring three variations:
- Rule-followers: Units and officers that do not reveal preferences before the market closes. In other words, rule-followers do not seek “one-for-one” matches and wait until the market closes.
- Rule-breakers: Units and officers that reveal true preferences before the market closes. Units offer “one-for-ones” to their top choices, and if accepted, they stop. Similarly, officers accept the best offer presented and inform units if they received a better offer.
Overall Procedure
- Generate preference lists based on randomly generated desirabilities.
- Each unit submits offers to their top choice. If the officer accepts, then the unit stops unless the officer accepts a different match (unless they’re a liar, in which case they keep making offers). The officers accept offers if they a) have no match or b) find a better match (in which case they notify the other unit that they’ve found a better match). If the officer is a liar, they verbally “accept” all offers.
- Anyone who does not have a valid match gets matched at the end by the Gale-Shapley Algorithm.
Results
All results will compare the average preference attained for both units and officers. For example, if everyone gets their first choice, then the average preference attained is 1 for both units and officers. Nice!
Additionally, I will use the results of the Gale-Shapley algorithm as a baseline. It’s worth emphasizing that Gale-Shapley yields the stable matching that is best for one group (units) and worst for the other (officers). This allows us to compare how variations compare to the Army’s intended “optimal” solution.
Plot Explainer
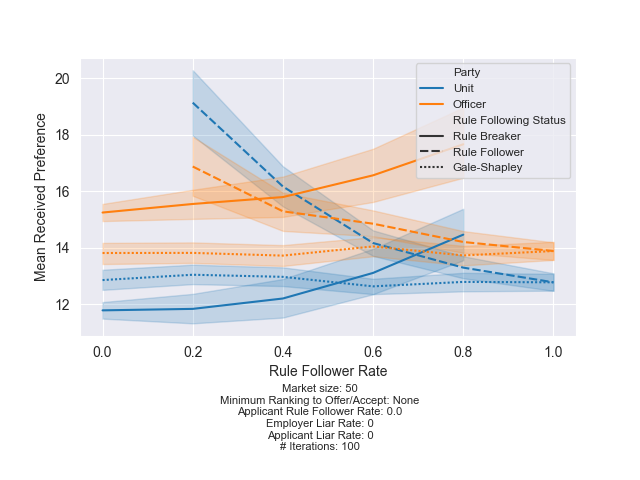
I’ll be using the same plot format to communicate results. On the y-axis, I show the average received preference for a particular subset of officers and units. The x-axis shows whatever parameter I am varying; in the below plot, it is the rule follower rate. In this example, the rule breaking units (solid blue), receive on average their 12th choice when no one follows the rules. Units are shown in blue lines while officers are shown in orange lines. The shaded area surrounding the lines represent the standard deviation across the 100 trials.
The dotted line represents the Gale-Shapley results (baseline), while the solid line represents the results for a party rule-breaking. The dashed line represents the rule followers.
The other parameters for the simulation run are at the bottom of the plot. So, this was for a market of size 50, no minimum rank to offer/accept (so a unit will offer to every officer versus their top 10), etc.
Impact of Market Size on Choice
I was generally curious about how Gale-Shapley would respond to changing market sizes. Under my assumptions, units and officers on average match with a preference around 25%. This matches intuition, as the underlying distributions do not change with the increased scale.
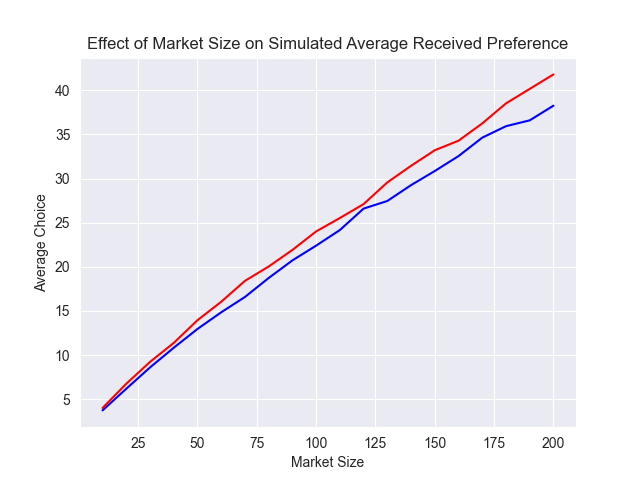
While I experimented with adjusting the market size, this has little impact on the shape of the results, so I will just show the results for a market of size 50.
Impact of Rule Breakers
In the following simulations, I vary the percentage of the units and officers who are “rule followers.” That is, some percentage of units and officers seek “one-for-one” matches. I will present results for two specifications side by side: the case where units will offer anyone until they get a match, and the case where units only make offers to their top 20, which represents the situation where a unit doesn’t have the time to go through their entire list offering one-for-ones.
Varying Numbers of Rule Breaking Officers
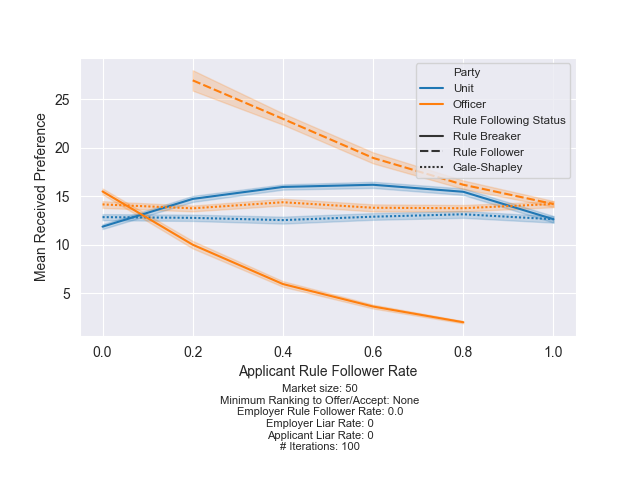
What happens if the units are breaking rules and the officer aren’t? Or vice-versa? The following plot shows the impact of changing the officer rule following rate while holding the unit rule following rate at 0 (i.e. every unit seeks a “one-for-one”).
| Units offer to everyone | Units offer to top 20 |
|---|---|
 |
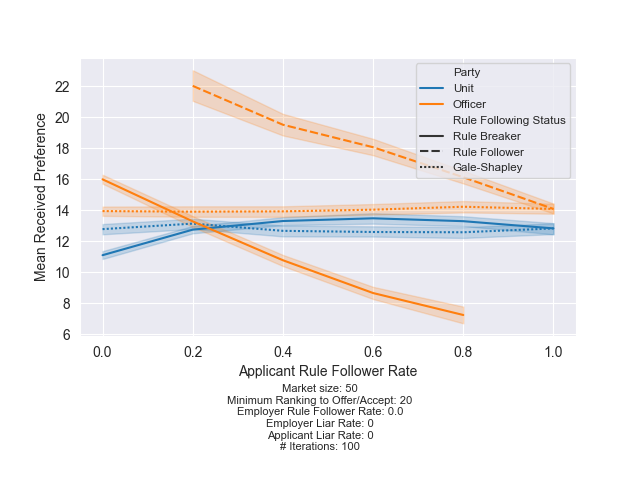 |
Finding 1: If all units are seeking “one-for-ones,” it is always better for officers to break the rules. You can see a large constant difference between the rule-following officers and the rule-breaking officers. Breaking the rules, while some officers follow the rules, allows the rule breakers to outperform the Gale-Shapley baseline.
Finding 2: If all units and officers break the rules, you get the same performance as Gale-Shapley because it is basically the same process. However, as officers follow the rules, the rule-followers underperform the baseline while the rule-breakers overperform.
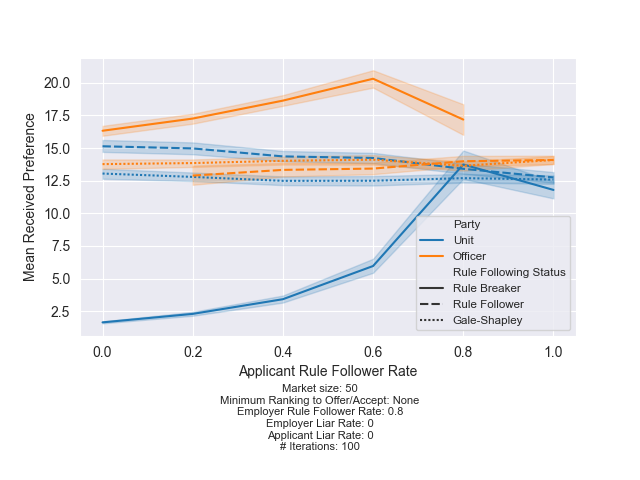
Now, consider what happens when 80% of the units follow the rules:
| Units offer to everyone | Units offer to top 20 |
|---|---|
 |
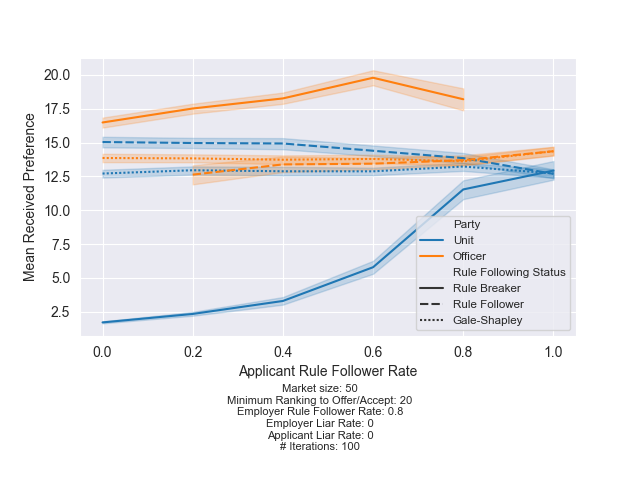 |
Finding 3: When most units follow the rules, the units that break the rules have a significant advantage. Consistent with finding 1, officers should also always break the rules.
Varying Numbers of Rule Breaking Units
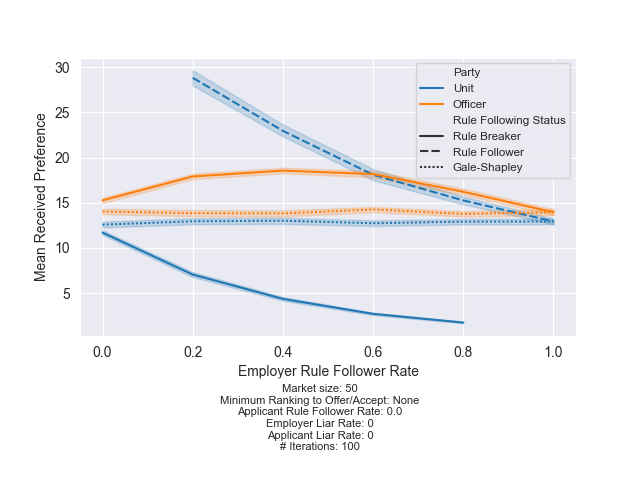
In the plot below, I show what happens when all the officers are rule breakers and will accept a “one-for-one” match. This result is clear. Finding 4: If officers are willing to accept “one-for-one” matches, units should always make offers. The units that follow the rules suffer much worse average preferences.
| Units offer to everyone | Units offer to top 20 |
|---|---|
 |
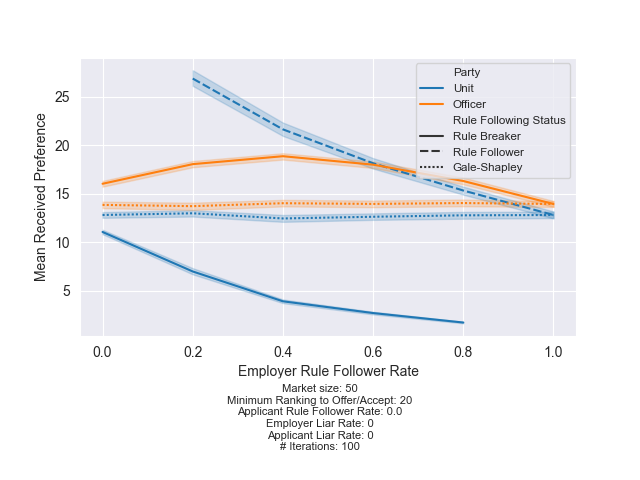 |
Game Theory
During the market, units and officers don’t know if the other is breaking the rules. However, given that there is never a penalty for breaking the rules and often an advantage over the rule followers, the optimal strategy is to seek a “one-for-one” match before the market starts.
Consider a scenario where most units follow the rules. In this scenario, a “defecting” unit has a lot to gain. So, one by one, units will seek “one-for-ones” to secure an advantage, until everyone is doing it. At this point, there is not much advantage compared to the baseline, but there is now a big penalty for following the rules.
$## Assumptions and Limitations
- Simulated data v. real data. I’m not sure the real data is better if it only includes the preferences as of market close because this is after significant tampering. If there was a snapshot of initial preferences, that would prevent the influence of informal bargaining. But yea, I simulated everything and I don’t know whether the distributions I used are close to the real distributions.
- Officers do not self-select based on ability. In reality, more competitive officers pursue more desirable jobs, while (self-aware) less competitive officers will pursue less desirable jobs. My modeling doesn’t take into account this effect. I could take this into account, by making an officer rank units with comparable desirability high, and units that are far above or beneath his desirability low.
- Preferences do not change as market develops. In reality, officers and units adjust their preferences on who is interested and how interviews go. You get more information as the process goes along and can better decide if a place is a good fit for you. Thus, when the marketplace ends, the rankings are some combination of initial preference, gained information and what is likely to pan out. I don’t take this reshuffling into account and don’t believe I could meaningfully model these idiosyncratic interactions without real data.
- Everyone ranks everyone. In real life, the officers are pretty good about ranking everyone but the units don’t, especially in large markets (100+ people). In my simulations, there is a complete list of rankings.
While these are shortfalls of my modeling, I believe the modeled scenario is close enough for the purposes of this investigation. I may not be able to quantify the gains of breaking the rules, but I believe I presented clear evidence to support intuition: you need to break the rules or you will be hurt by your integrity.
Recommendations
The “one-for-one” match process as I have modeled it hurts units and officers that abstain from it. But, if everyone is playing the game, it is not really an issue (we end up roughly getting Gale-Shapley). As it stands, the marketplace encourages behaviors that make both the units and officers worse off compared to what would have happened. Moreover, it seems to encourage lawlessness, as following the rules disadvantages you. It’s a collective action problem: as long as other people are breaking the rules, you are hurt by not also breaking the rules. I am not confident that “side channels” can ever be eliminated. For example, you might seek a match with someone who you’ve worked for before or your mentor might know them… In this case, the “old boys network” will prevail and frankly there’s not much to be done about this. Still, I think there’s room for improvement.
First and foremost, senior leadership needs to enforce the standard. Like any other organizational issue, it will only be fixed if important people are invested in it. The problem in this case is the senior leadership is self-interested: battalion commanders want the best person, so they will break the rules. Moreover, they don’t want to follow the rules when it only puts them at a disadvantage. Basically, at the general level, someone would have to coerce hirers into following the rule. This would require whistleblowers and punishments. Officers and units would have to report rulebreakers they encounter throughout the marketplace. The rulebreakers would need to be punished with an unsatisfactory choice. Beyond the suboptimal matches, rules that are never followed generally undermine the authority of the organization.
Second, HRC should publish the results in a more timely manner. In some cases, people just want to resolve uncertainty and not wait several months to find out where they are moving. One of the most challenging aspects of military life is frequent moves, and it’s frustrating for the officers to have to wait with their fate in the ether for so long. This is undoubtedly some part of the reason people desperately seek one-for-one matches. I’ll put it this way: if you were going to move to Kuwait for a year, would you rather know now, or find out in three months. While I am not privy to the details behind the considerable delay, there has to be room for improvement.
Finally, HRC representatives should prepare officers for the reality, rather than the ideal. In my branch manager’s pre-marketplace brief, he implied that “one-for-one” matches are a rarity. But they’re not! In fact, I think every unit in my marketplace disclosed its preferences! In the interest of the officers, branch managers should give some advice on what to do if you receive an exploding offer, how to respond to a superior officer pressuring you to commit, etc.
Appendix
I tried pretty hard to implement some version of lying. Its not uncommon for officers to tell units they are their top choice when they aren’t. Similarly, I encountered a scenario where a unit offered both me and another officer a match… we clearly can’t both get the same position. I made an attempt but the results were bogus. It is generally difficult to effectively model situations with imperfect information and individual decisions. I left out my results because I have no confidence in them. Adding another random process in the mix is not particularly enlightening as there are already so many.
-
This is hard to explain succinctly, so I refer you to the wikipedia article. ↩
-
It is a known point of frustration that it takes so long to learn the results. There is some routing list that must approve the results, as well as exceptions that have to be made for people married to another Soldier, people with special family care needs, etc. ↩
-
For aesthetic reasons, I wanted the desirabilities to be on a scale from 0 to 100, so I made the mean 50 and standard deviation 20. For this parameterization, the probability of drawing a 0 or 100 is .006, for example. ↩
-
This noise term was chosen arbitrarily. I looked at the resulting distributions based on various standard deviations until it matched rough intuitions. ↩